Kursthemen
-
Beschreibende Statistik
-
Zur Vorbereitung auf die schriftliche Reifeprüfung in Mathematik stellt das Bildungsministerium einen Aufgabenpool zur Verfügung, der auch Aufgaben zur beschreibenden Statistik enthält:
- WS1.1: Werte aus tabellarischen und elementaren grafischen Darstellungen ablesen (bzw. zusammengesetzte Werte ermitteln) und im jeweiligen Kontext angemessen interpretieren können
- Schulstufe 9: https://gwb.schule.at/mod/quiz/view.php?id=47144
- Schulstufe 10: https://gwb.schule.at/mod/quiz/view.php?id=47145
- WS 1.2: Tabellen und einfache statistische Grafiken erstellen, zwischen Darstellungsformen wechseln können
- Schulstufe 10: https://gwb.schule.at/mod/quiz/view.php?id=47162
- WS 1.3: statistische Kennzahlen (absolute und relative Häufigkeiten; arithmetisches Mittel, Median, Modus, Quartile, Spannweite, empirische Varianz/Standardabweichung) im jeweiligen Kontext interpretieren können; die angeführten Kennzahlen für einfache Datensätze ermitteln können
- Schulstufe 10: https://gwb.schule.at/mod/quiz/view.php?id=47161
- WS 1.4: Definition und wichtige Eigenschaften des arithmetischen Mittels und des Medians angeben und nutzen, Quartile ermitteln und interpretieren können, die Entscheidung für die Verwendung einer bestimmten Kennzahl begründen können
- WS1.1: Werte aus tabellarischen und elementaren grafischen Darstellungen ablesen (bzw. zusammengesetzte Werte ermitteln) und im jeweiligen Kontext angemessen interpretieren können
-
- Daten in ihrer Gesamtheit erfassen
- Unterschiedlichkeiten analysieren
- Trends erkennen
.
→ Mittelwerts- und Streuungsmaße→ Klassifizierungen > Lektion "Gestaltung thematischer Karten mit ArcGIS-Online"→ Beschreibung durch Modelle→ > Lektion "Visualisierung in Diagrammen"
-
Häufigkeitsverteilung
- "Funktion" (stetig oder diskret) der Verteilung von Werten in einem Datensatz
- grafische Darstellung der Verteilung eines Datensatzes geeignet zur statistischen Beschreibung von Datensätzen
- Histogramm: Häufigkeitsverteilung kardinal skalierterMerkmale
- Entscheidend für die Darstellung (diagrammatisch, kartografisch, etc.) und Interpretation eines Datensatzes!

https://www.youtube.com/watch?v=cBuxgw-ZvV0
https://chartio.com/learn/charts/histogram-complete-guide/
-
-
Die Ausprägungen einzelner Merkmale werden anhand von Skalen gemessen, welche sich aufgrund ihrer formalen Eigenschaften einem von vier verschiedenen Skalentypen zuordnen lassen. Die vier Skalentypen, welche man in Anlehnung an STEVENS (1946) als Nominal-, Ordinal-, Intervall- und Rationalskala bezeichnet [1], unterscheiden sich voneinander dadurch, dass je nach Skalentyp Beziehungen unterschiedlicher Qualität zwischen den einzelnen Merkmalsausprägungen hergestellt werden können.
Diese Zuordnung einer Skala zu einem Skalentyp ist insofern von grundlegender Bedeutung, da durch diesen automatisch jene statistischen Techniken festgelegt werden, welche man auf die Variable, deren Ausprägungen anhand der jeweiligen Skala gemessen worden sind, anwenden darf.

-
Thomas Schöftner (2016) Variablenarten nach Ihem Skalenniveau unterscheiden.- Linz. Video. Web: https://youtu.be/gTJ5O5GNzt4 (22.11.2017)
-
Linktipp: Universität Zürich (2017) Methodenberatung. Zürich. Web: http://www.methodenberatung.uzh.ch/de.html (22.11.2017)
-
-
-
Neben der zuvor besprochenen Unterteilungsmöglichkeit von Variablen in nominal-, ordinal-, intervall- und rationalskalierte, welche im Hinblick auf praktische Anwendungen zweifelsohne als die bedeutendste angesehen werden kann, existieren noch zahlreiche weitere Arten, Merkmale zu klassifizieren. Von diesen Klassifikationsmöglichkeiten ist die Unterscheidung in diskrete und stetigen Variablen von grundlegender Bedeutung.
- (statistisch) diskrete Variable (engl. discrete variable), das sind Variable, welche nur endlich viele Merkmalsausprägungen besitzen, und
- (statistisch)stetige Variable (engl. continuous variable), das sind Variable, welche - zumindest in einem bestimmten Intervall - jede beliebige und somit unendlich viele Merkmalsausprägungen annehmen können,
Diskrete Variable sind beispielsweise die Merkmale „Beruf“, „Schulnote“ oder „Einkommen“, stetige Variable hingegen z. B. die Merkmale „Temperatur“, „Körpergewicht“ oder „Entfernung“.

Als Folge der begrenzten Genauigkeit von Messinstrumenten lassen sich in der Praxis jedoch auch stetige Variable nur diskret erfassen; so ist z. B. die „Temperatur“ eine stetige Variable, welche allerdings nur so exakt gemessen werden kann, wie es das jeweilige Thermometer gestattet. Vice versa behandelt man häufig diskrete Variable wie stetige. So wird im Rahmen praktischer Aufgabenstellungen beispielsweise vorausgesetzt, dass es sich bei der Variablen „Einkommen“ nicht um eine diskrete (Ausprägungen: ganzzahlige positive Centbeträge), sondern um eine stetige handelt.
Resümierend lässt sich zum zuletzt Gesagten somit festhalten, dass die - aus theoretischer Sicht problemlos erscheinende - Festlegung, ob es sich bei einer Variablen um eine diskrete oder um eine stetige handelt, im Rahmen praktischer Anwendungen in vielen Fällen nicht ohne weiteres möglich ist, sondern erst durch die konkrete Fragestellung entschieden wird.
Im geografischen Kontext spricht man von geografisch stetigen Merkmalen, wenn jeder Ort auf der Erde eine Merkmalsausprägung besitzt (z. B. Umgebungstemperatur, Höhe, Druck) und von geografisch diskreten Merkmalen, wenn nur bestimmte Orte eine Merkmalsausprägung besitzen (z. B. Straßen, Bäume, Gewässer) oder diese Ausprägung in statistische Einheiten (Regionen) erfasst werden (z. B. Bevölkerungsdichte einer Gemeinde, Arbeitslosenquote einer Region, Wählerstimmen einer Partei in einem Zählsprengel).
-
-
-
Als Lageparameter bezeichnet man jene Kennzahlen, deren Aufgabe die Charakterisierung der Lage einer Häufigkeitsverteilung durch einen zentralen Wert ist. Die meistverwendeten Lageparameter sind Modus, Median sowie arithmetisches und geometrisches Mittel.
Nachfolgende Tabelle enthält eine Zusammenfassung, wobei die für einen Skalentyp jeweils am besten geeigneten Parameter durch Fettschrift gekennzeichnet sind. Details entnehmen Sie bitte der Textseite im Link.
Skalentyp
Lageparameter
Nominalskala
Modus
Ordinalskala
Median, Modus
Intervallskala
arithmet. Mittel, Median, Modus
Rationalskala
geometr. Mittel, arithmet. Mittel, Median, Modus
-
Welche der folgenden Aussagen sind zutreffend?
Autor: Thomas Schöftner (2017). Linz
-
-
-
Die Tabelle enthält eine Zusammenfassung, wobei die für einen Skalentyp jeweils am besten geeigneten Parameter durch Fettschrift gekennzeichnet sind. Details entnehmen Sie bitte der Textseite im Link.
Skalentyp
Streuungsparameter
Nominalskala
Keine
Ordinalskala
Spannweite
Intervallskala
Varianz, Standardabweichung, Spannweite
Rationalskala
Variationskoeffizient, Varianz, Standardabweichung, Spannweite
-
Für normalverteilte Merkmale gilt, dass innerhalb der Entfernung einer Standardabweichung nach oben und unten vom Mittelwert etwa 68,2% der Merkmalsausprägungen ("Messwerte") liegen, innerhalb von zwei Standardabweichungen etwa 95,4%.

Quelle: wikipedia.org
-
-
-
Die Korrelationsanalyse hat die Aufgabe, die Art sowie die Stärke des Zusammenhanges zwischen den jeweiligen Variablen durch geeignete Maßzahlen zu charakterisieren.
Wie die Theorie zeigt, können derartige Maßzahlen, welche man als Korrelationskoeffizienten bezeichnet, sowohl für ordinal- als auch für intervall- und rationalskalierte Variable ermittelt werden.
.
- Alter vs. Gehalt: R stark positiv

.
- Alter Ehemann vs. Alter Ehefrau: R stark positiv

.
-
Seehöhe vs. Umgebungstemperatur: R stark negativ

.
- Arbeitslosenrate vs. Abstand bei der letzten Wahl: R ~ 0

-
1.) Störche und Geburtenrate
2.) Schuhgröße und Einkommen
-
Die Bedeutung des Pearsonschen Korrelationskoeffizienten für die Regressionsanalyse liegt darin, dass er wesentliche Information betreffend das Verhältnis zwischen gegebenen Daten und Regressionsgeraden enthält.
- Zum einen legt das Vorzeichen des Pearsonschen Korrelationskoeffizienten fest, ob ein direkter oder indirekter Zusammenhang zwischen zwei Variablen besteht, und ob somit die Regressionsgerade monoton wächst (sofern r > 0 ist) oder monoton fällt (sofern r < 0 ist).
- Zum anderen bringt der Betrag des Pearsonschen Korrelationskoeffizienten die Stärke des linearen Zusammenhanges zwischen zwei Merkmalen zum Ausdruck und stellt somit eine Maßzahl für die Güte der Approximation der gegebenen Datenpunkte durch die Regressionsgerade dar (siehe nachfolgende Abbildungen).
-
Zwei Korrelationskoeffizienten:
- Pearson Correlation Coefficient (PCC, Pearson's r): Messung des Zusammenhanges zwischen intervall- bzw. rationalskalierten Variablen
- Spearman's Rank Correlation Coefficient (Spearman's
/rho): Beurteilung des Zusammenhanges zwischen ordinalskalierten Merkmalen
-
Räumliche Autokorrelation
Die "Räumliche Autokorrelation" gibt an, ob verschiedene Regionen in Bezug auf ein dargestelltes Merkmal gehäuft ("Cluster"), regelmäßig oder zufällig im geographischen Raum verteilt sind.
Das Werkzeug "Räumliche Autokorrelation" eines GIS gibt fünf Werte zurück: Moran's I-Index (Grad der Clusterung im Gesamtdatensatz), erwarteter Index, Standardabweichung/Varianz, z-Ergebnis (Signifikanzlevel der räumlichen Verteilung) und p-Wert (Indikator für Signifikanz).
Wenn die Aussage signifikant ist (das z-Ergebnis oder der p-Wert auf statistische Bedeutung hinweist), zeigt ein positiver Moran's I-Indexwert eine Tendenz zur Cluster-Bildung und ein negativer Moran's I-Indexwert eine Tendenz zur Streuung an.
Bildliche Darstellung der räumlichen Verteilung von Datensätzen:
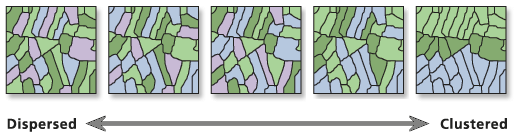

Zusammenhang zwischen Standardabweichung und räumlicher Autokorrelation
z-Transformation: Erwartungswert 0, Standardabweichung 1
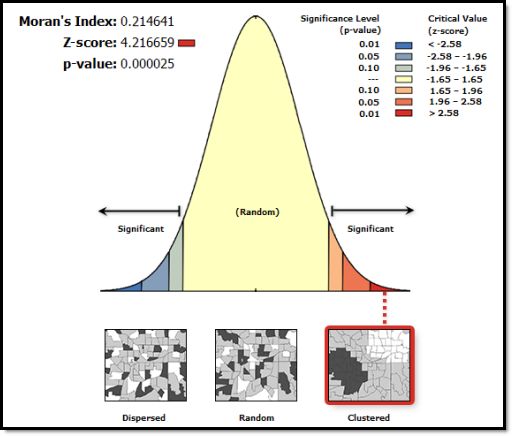
Beispiel: Local Moran's I:

- Parameter
- n ... Anzahl der Punkte
- xi ... Attributwert am Punkt i
- xj ... Attributwert am Punkt j
- x̄ ... Mittelwert von x (aller Punkte)
- wij ... räumlicher Gewichtungsfaktor
- i != j
- Normalisierung über:
- Summe aller Gewichte
- Summe aller quadrierten Differenzen von xi und x
Schematisches Beispiel der Funktionalität der räumlichen Gewichte:

- Parameter
-
-
-
- Wählen Sie die Option In Map-Viewer öffnen.
Zunächst zeigt die Karte alle Gemeinden Österreichs, farblich nach Bundesland unterschieden. - Mit dem Werkzeug Style ändern sind weitere Eingaben möglich.
 in
in 
- Zunächst als Attribut die Einwohnerzahl einstellen.
- Dann die Optionen des Darstellungsstils ändern.
- Daten klassifizieren auswählen, die Anzahl der Klassen und die Art der Klassifizierung festlegen.
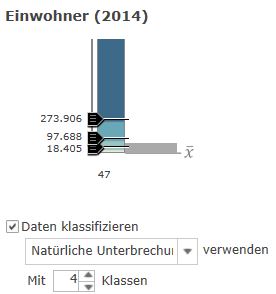
- Natürliche Unterbrechung: An "Lücken" in den Datenwerten werden Klassengrenzen gesetzt.
- Gleiches Intervall: Die Klassen sind alle gleich breit.
- Standardabweichung: Die Klasseneinteilung folgt dem Streuungsmaß.
- Quantil: In jeder Klasse sind gleich viele Regionen.
- Manuelle Unterbrechung
-
- Mit Klick auf die Zahlen (Klassengrenzen) neben dem Diagramm werden diese manuell eingestellt .
- Mit OK und Fertig abschließen
Die Sinnhaftigkeit dieser Darstellungsform, die Art der Karte bzw. des Kartogramms, werden wir im Lernkurs Thematische Kartographie diskutieren. Im Moment genügt die Standardeinstellung, welche einen schnellen optischen Eindruck liefert.
Die Daten wurden von Robert Vogler (2016 - Universität Salzburg) zusammengestellt. Herzlichen Dank!
- Wählen Sie die Option In Map-Viewer öffnen.
-